
A loop that rewrites its own code is powerful until it isn't. The moment mutation crosses from "suggests changes" to "commits changes," you need containment, stop signals, and controlled autonomy. Not blind optimism.
This lesson closes the course. We tie the genome, orchestrator, observability, self-challenging judge, and test-time search into one defensible system. The glue is production safety.
Prerequisites
- Lessons 01 through 06 of this course (mutation engine, genome, orchestrator, observability, self-challenging judge, test-time search)
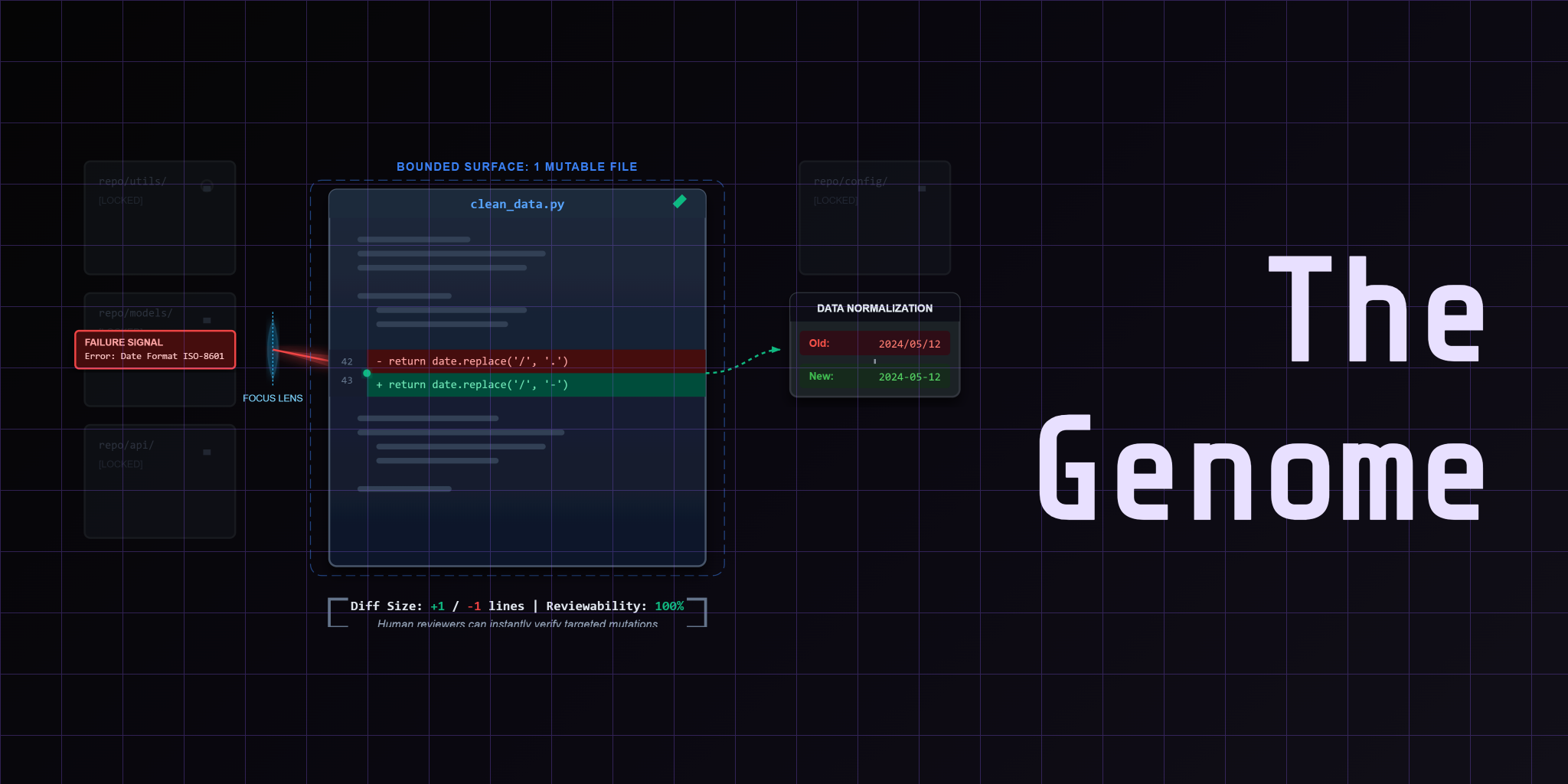
- Understanding of the bounded mutation contract: one mutable file, one fixed judge, one artifact trail
- Basic Python (the examples use
subprocessand file operations)
The Self-Driving Car Analogy
Motion alone is not the point. You don't prove safety by showing a car drives fast. You prove it by showing the car stops when it should.
The same logic applies to self-rewriting code. A loop that proposes mutations is just an engine. Safety is the containment around it — sandboxing, trust controls, and reset. Without these, a bad mutation can hang the process, exhaust memory, or corrupt the genome. Without them, you have an engine with no brakes.
Containment First
try/except is not enough. An exception handler catches errors in your process. It does not catch a mutation that spawns an infinite loop, a subprocess that never exits, or a file write that corrupts the genome. You need process-level isolation.
The sandbox runs the genome in a separate subprocess with a hard timeout. It captures stdout, stderr, and exit codes. If the genome hangs, the sandbox kills it. If it crashes, the sandbox records the failure. The main loop never blocks.
Ten seconds. If the genome doesn't finish, the sandbox moves on. The main loop stays alive and the evidence trail records the timeout.
The trade-off is clear. Subprocess isolation adds overhead on every round. That latency compounds with test-time search. But a contained failure is still data. An uncontained failure is a production incident.
The Trust Ladder
Autonomy should rise and fall with evidence. The trust ladder has three modes, and it moves both ways.
Review mode is the baseline. The loop proposes mutations. A human or the judge reviews them before they commit. Slow but safe. Use it when the loop is new or the mutation cost is high.
Notify mode is the middle ground. The loop commits mutations but sends a notification after each round. You get a signal. You can intervene. But the loop doesn't block on your response.
Auto-approve mode is full autonomy. The loop commits without human review. Use it when the loop has a track record and the sandbox is tight.
Three bad rounds in a row? Demote to review. Five good rounds? Promote to notify. The system doesn't assume trust. It earns it through a sliding window over recent outcomes.
Reset as Control
Reset is not deletion. Reset is recovery.
When you reset the loop, you restore the starter genome. You bring clean_data.py back to clean_data_starter.py. The .output/ artifacts stay. The evaluation history stays. The strategy trail stays. Reset gives you a clean baseline without erasing evidence.
Without reset, a degraded loop has no recovery path. You end up manually reconstructing the starter genome from memory. With reset, you can always start fresh and compare against the evidence trail.
The Layered Defense Shell
Safety is not one tool. It is layers. Sandboxing at the core. Anomaly detection through the judge around it. Permission control through the trust ladder on top. Each layer catches what the layer below misses.
| Layer | Catches | Fails If |
|---|---|---|
| Sandbox | Crashes, hangs, OOM | Timeout is too long |
| Judge | Score regressions | Judge is too lenient |
| Trust Ladder | Pattern drift | Window too small |
Weakness in one layer becomes the responsibility of the next. That is how layered defense works.
Tripwires
A tripwire stops the loop before it causes damage. A single bad round is data. Three bad rounds in a row is a pattern. Ten is a signal that something is fundamentally wrong.
Common tripwires:
- Score floor — stop if the genome drops below a minimum score
- Consecutive failures — pause after N rounds with no improvement
- Timeout frequency — the mutation surface is too aggressive if the sandbox kills too often
- File size growth — if the genome grows without score improvement, it's memorizing not learning
The hardest tripwire to set is the score floor. Too high and the loop never explores. Too low and the loop degrades before the tripwire fires. Calibrate against the starter genome score: below the baseline but above random noise.
Trade-offs
Safety costs. Autonomy costs. The question is which cost you can afford.
| Safety Feature | Cost | When It Matters Most |
|---|---|---|
| Sandboxing | Per-round latency | Test-time search (many candidates) |
| Trust Ladder | Review overhead early | New genome, unknown surface |
| Reset | Loss of near-working mutations | When exploration is narrow |
| Tripwires | Premature stops | Near a breakthrough |
Use review mode when the cost of a bad mutation is high. Use auto-approve when the sandbox is tight and the loop has a track record. Always keep reset available. Always keep the tripwires calibrated.
Course Conclusion
Seven lessons. One system.
You started with the mutation engine — an LLM that proposes changes to a bounded genome. Then you built the genome boundary, the orchestrator control shell, and the observability layer. You made the judge self-challenging. You added test-time search for parallel exploration.
This lesson ties it together. Production safety is the shell that makes the loop runnable. The sandbox contains failures. The trust ladder governs autonomy. Reset provides recovery. Tripwires catch drift. Layered defense ensures weakness in one layer is caught by the next.
A self-evolving system is only as good as its safety controls. Build the loop. Build the shell. Keep both explicit.
Related Reading
- Previous: Lesson 06: Test-Time Search & Re-Ranking — Why one candidate is usually not enough and how best-of-N search works.
- Project anchor: CleanLoop Example — See how sandboxing, autonomy, reset, and observability fit together in one runnable project.
- Series overview: Building a Self-Evolving Data Engineer — 7 Lessons from the CleanLoop — Revisit how the course builds from boundary to safety.
Next Steps
This article covers production safety — the containment, trust, and recovery mechanisms that make a self-rewriting loop defensible in production. The full lesson includes a walkthrough of sandboxing, trust ladder modes, reset behavior, and tripwire calibration.
Watch Lesson 07: Production Safety: Sandboxing, Trust, and Reset
Explore the code: Cleanloop on GitHub
CLI commands to try:
python util.py sandbox --timeout 10— run the genome in a sandboxed subprocesspython util.py autonomy --rounds 5— run five rounds through the trust ladderpython util.py reset— restore the starter genome
The full course and example code are open source. The loop only works when safety is the shell, not an afterthought.
This article concludes the Self-Evolving Data Engineer series. Seven lessons. One principle: keep the control shell explicit and the mutation surface bounded.