
You can give an LLM every failure log in the world. But without a control shell that reads the evidence, proposes a fix, verifies the result, and decides survival, you don't have a loop. You have a suggestion engine with no selection rule.
CleanLoop is the runnable example that proves the architecture. It is not a toy. It is a complete, self-contained project you can clone, run, and inspect — from the first mutation to the final dashboard trace.
Prerequisites
- Python 3.10+ and a working
pip - An LLM endpoint (OpenAI-compatible). The loop calls the model for mutation proposals.
- Familiarity with data pipelines and ETL concepts
- No AutoGen experience required — the project is self-contained
What Is CleanLoop?
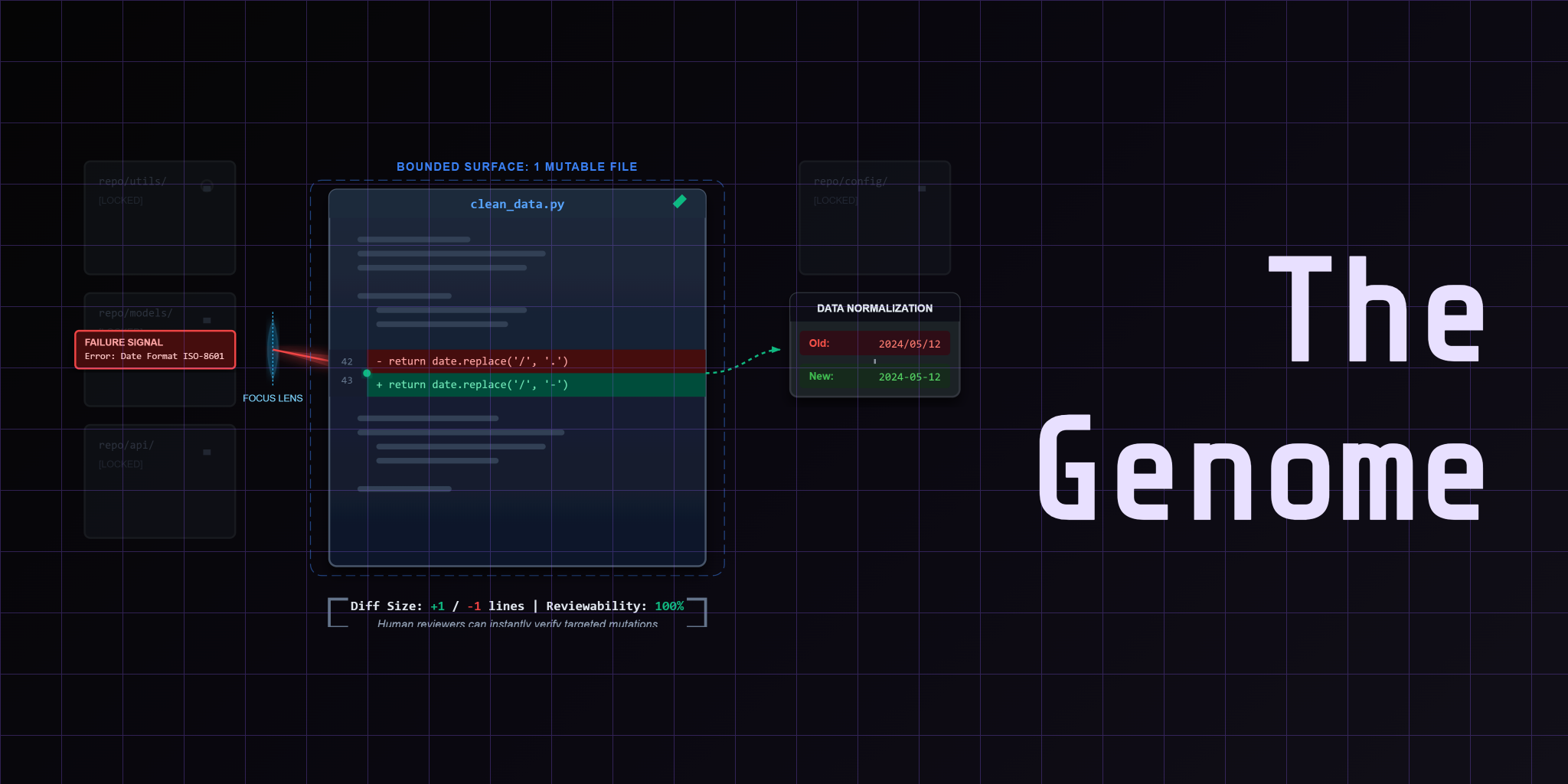
CleanLoop is a bounded self-improving loop over a finance data-cleaning pipeline. It takes messy CSV input, runs a mutable Python genome against it, grades the output with a fixed referee, and uses an LLM to propose mutations when the score is below perfect.
The core claim is simple: one mutable file, one fixed judge, one artifact trail.
That boundary is what keeps the loop auditable. The genome is a single Python file. The referee is immutable — the agent cannot modify it. Every round produces structured artifacts you can inspect after the fact.
This is not a generic agent sandbox. It is a deliberate architecture for data engineering loops where verification matters more than speed.
Architecture
CleanLoop splits into four stations. Each one has a job. Each one stays explicit.
The orchestrator (loop.py) coordinates the round. It runs the genome, calls the referee, compresses failures into a focus area, requests a mutation from the LLM, re-evaluates the candidate, and decides commit or revert. One round is one atomic experiment.
The referee (prepare.py) is the fixed judge. It evaluates the genome's output against binary assertions — row-level checks for currency normalization, date parsing, deduplication, and reconciliation. This file is locked. The agent must never modify it.
The challenger (challenger.py) generates adversarial data. It uses the LLM to create progressively harder messy CSVs that target the genome's known weaknesses. As the cleaner improves, the challenger makes harder data. That is auto-curriculum.
The sandbox (sandbox.py) runs the genome in an isolated subprocess with timeout enforcement. The genome cannot access loop state. If it hangs, the sandbox kills it. That containment is what makes the loop safe enough to run in production.
| Station | Role | Key File |
|---|---|---|
| Orchestrator | Coordinates read → propose → verify | loop.py |
| Referee | Binary pass/fail judge | prepare.py |
| Challenger | Adversarial data generation | challenger.py |
| Sandbox | Subprocess isolation + timeout | sandbox.py |
The File Layout
CleanLoop ships with a focused set of files. Each one has a single responsibility.
| File | Role |
|---|---|
loop.py | Main orchestrator (read, propose, verify, revert) |
autogen_runtime.py | Structured proposal helpers (the LLM seam) |
reranker.py | Best-of-N candidate generation |
prepare.py | Fixed referee (judge — immutable) |
challenger.py | Adversarial data generation |
sandbox.py | Subprocess isolation + timeout |
autonomy.py | Trust ladder (review → notify → auto) |
dashboard.py | Streamlit observability UI |
dashboard_metrics.py | Metric builders for the dashboard |
tracing.py | Run-event, row-decision, proposal-event writers |
util.py | CLI wrapper (status, verify, reset, loop, etc.) |
clean_data.py | The mutable genome |
clean_data_starter.py | Immutable baseline genome |
.output/ | Artifact directory (history, strategy, traces) |
.input/ | Input CSV directory |
The genome is the only file the loop modifies. Everything else stays stable. That is the boundary.
Running It
The project ships with a single CLI entry point: util.py. The flow from clone to first loop is straightforward.
That is the essential flow. Check state, validate, reset to the starter genome, run three bounded rounds, then inspect the evidence. Each round reads the genome, judges the output, proposes a fix, re-evaluates, and commits or reverts.
The optional commands widen the search or stress-test the pipeline:
One bounded round
The CLI keeps the loop explicit from validation through inspection.
Start by proving the repo is healthy before the first mutation runs.
Then run a bounded loop, inspect the artifacts, and verify that commit-or-revert stays visible.
Reranking runs best-of-N search. Challenger generates adversarial data. Sandbox tests containment. Autonomy checks the trust ladder. And dashboard opens the Streamlit UI for visual inspection.
The Artifact Trail
Every round produces structured artifacts. That trail turns iteration into learning.
| Artifact | What It Shows |
|---|---|
.output/finance_eval_history.json | Score deltas across rounds |
.output/finance_strategy.json | Metacognition snapshots (focus area + guidance) |
.output/traces/run-events.jsonl | Per-round runtime events |
.output/traces/row-decisions.jsonl | Row-level trace decisions |
.output/traces/proposal-events.jsonl | LLM proposal events (attempt, tokens) |
.output/logs/finance_round_logs.jsonl | Structured round logs |
Without these artifacts, each round is a transient event. With them, you can chart score movement, trace why the loop shifted focus, and prove the system is actually improving.
What You Can Learn
Running CleanLoop teaches several concrete patterns:
Bounded mutation. The genome is one file. The judge is fixed. The trail is visible. That boundary is what makes the loop auditable.
Revert is progress. When the judge rejects a mutation, the loop restores the previous genome. No partial state. No drift. The baseline stays clean.
Metacognition through compression. The loop does not send raw failures to the LLM. It compresses repeated failures into one focus area and one coaching hint. That narrowing is evidence-driven — not magic.
Trust as a function of track record. The autonomy ladder starts at full human review. As the agent proves itself, the loop graduates to notify-then-apply, then async review, then full auto. Any critical failure resets to supervised.
Observability is not optional. You cannot trust a loop you cannot inspect. The dashboard, the traces, and the history log are not nice-to-haves. They are the foundation.
When to Use This Pattern
CleanLoop is not a general-purpose agent framework. It is a deliberate architecture for specific problems.
Use this pattern when:
- You have a bounded mutation surface (one or a few files that can change)
- You have a deterministic judge (binary pass/fail criteria)
- You need auditability (every decision must be reviewable)
- The cost of a bad mutation is low enough to revert
- You can tolerate the latency of full re-evaluation per round
Do not use this pattern when:
- The mutation surface is too broad (multiple interdependent systems)
- The judge is subjective (no clear pass/fail criteria)
- You need sub-second iteration (full re-evaluation is slow)
- You cannot isolate the mutation from the rest of the system
The pattern works best for data pipelines, code generation, and configuration tuning. It struggles with open-ended creative tasks or systems where the judge itself is stochastic.
Trade-offs
The loop is slower than a raw LLM call. Each round requires a full re-evaluation. That latency is intentional. Speed without verification is not improvement — it's just faster guessing.
The bounded genome means the loop cannot fix structural problems. If the pipeline architecture is wrong, mutating one file won't help. You need to widen the boundary first.
The fixed judge is a double-edged sword. It keeps the loop auditable, but it can only measure what the assertions cover. Rows that the judge doesn't check are invisible to the loop.
Related Reading
- Series overview: Building a Self-Evolving Data Engineer — 7 Lessons from the CleanLoop — Start with the full course map, then drill into the lesson that matches the mechanism you want to study.
- Lesson 01: The Mutation Engine — Why the loop needs a bounded contract before the first mutation runs.
- Lesson 02: The Genome — Why the mutation surface must stay narrow.
- Lesson 03: The Orchestrator — The control shell around the LLM.
- Lesson 04: Observability & Feedback — External memory for every round.
- Lesson 05: Judge & Self-Challenging — Adversarial data and auto-curriculum.
- Lesson 06: Test-Time Search — Best-of-N reranking.
- Lesson 07: Production Safety — Sandboxing, autonomy ladders, and deployment.
Next Steps
The full seven-lesson course walks through this architecture from first principles to production deployment. Each lesson includes a video walkthrough, a live demo, and hands-on exercises.
Course playlist: Self-Evolving Data Engineer on YouTube
Example code: CleanLoop on GitHub
Tutorial site: LocalM Tuts
The loop only works when the control shell stays explicit, the judge stays fixed, and the LLM stays bounded to one station.