Building a Self-Evolving Data Engineer — 7 Lessons from the CleanLoop
A seven-part map of the CleanLoop architecture, from bounded mutation and genome design to observability, reranking, and production safety.
Read articleA seven-part map of the CleanLoop architecture, from bounded mutation and genome design to observability, reranking, and production safety.
Read articleCategories and tracks stay structural. Series and tags stay editorial.
Series pages gather related essays without forcing that label into the route structure.
Tags cut across structure when one concept shows up in multiple posts.
9 posts use this tag.
9 posts use this tag.
1 post use this tag.
1 post use this tag.
1 post use this tag.
1 post use this tag.
Every card exposes the actual navigation targets instead of making the whole surface one big link.
Why sandboxing, trust ladders, reset controls, and tripwires are mandatory before self-rewriting code touches production.
Why best-of-N search outperforms one-shot mutation proposals when the search space is wide and the judge is stable.
Why a fixed judge needs a separate challenger that makes the data harder without moving the goalposts.
Why durable artifacts, row-level traces, and operator-facing dashboards turn mutation loops into auditable systems.
Why the orchestrator must read evidence, request one bounded mutation, verify it, and revert failure cleanly.
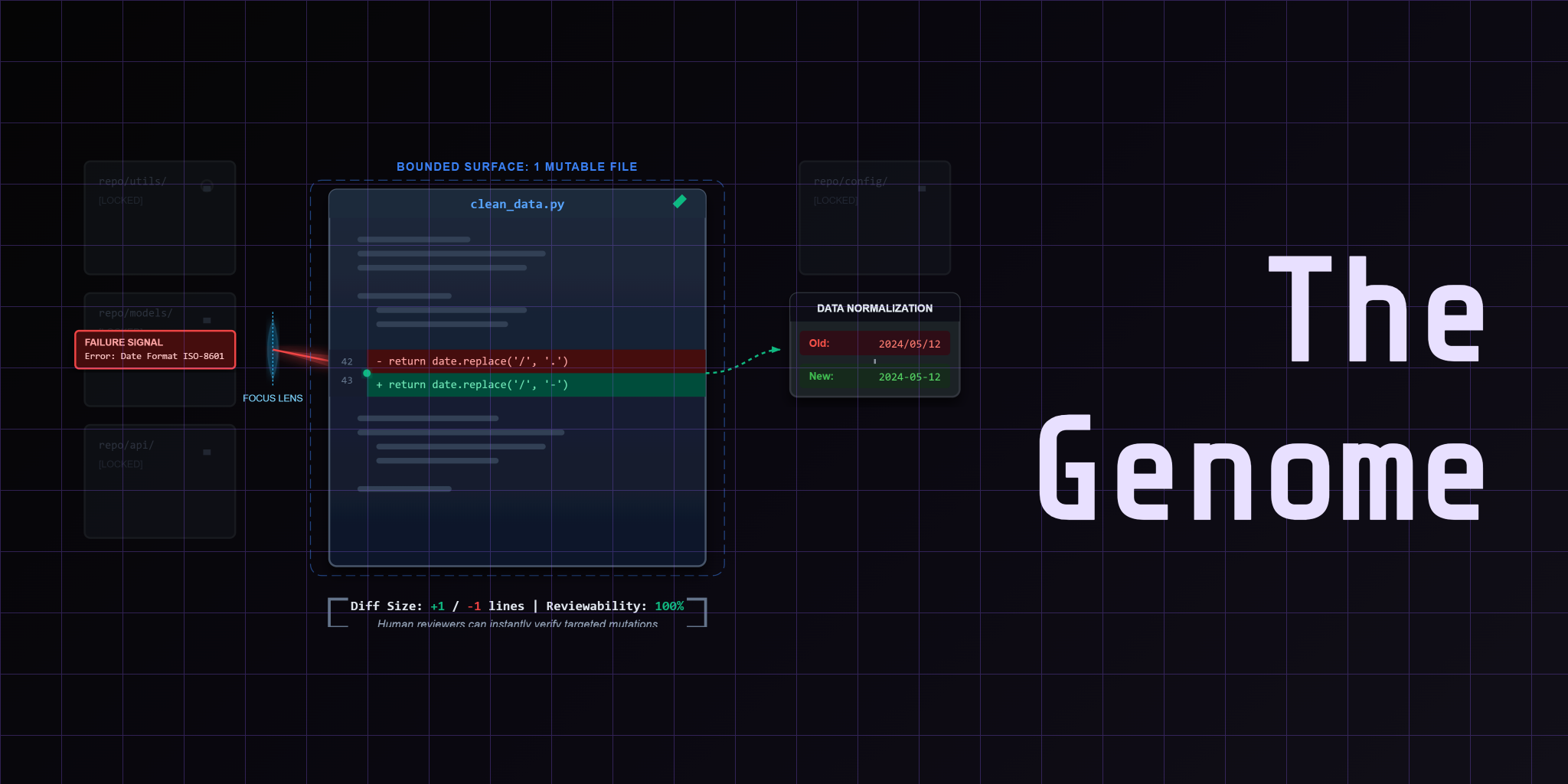
Why self-improving systems need one mutable genome, one fixed judge, and clean rollback boundaries.
Why bounded mutation contracts matter before the first AI-generated repair attempt touches your pipeline.
A repo-first walkthrough of CleanLoop, the bounded mutation loop that repairs finance pipelines with one mutable genome and one fixed judge.
A seven-part map of the CleanLoop architecture, from bounded mutation and genome design to observability, reranking, and production safety.