
Your pipeline does not fail because data is hard. It fails because a human still reads the failure, picks the next fix, and carries the loop memory forward.
That bottleneck cannot scale. The next iteration of data engineering isn't about writing better code. It's about building an architecture where the loop carries its own memory.
Prerequisites
- Familiarity with data pipelines and ETL concepts
- Basic understanding of LLMs and agent frameworks
- Python experience (the examples use
autogen-agentchat,pandas, andstreamlit) - No AutoGen experience required — this article builds from first principles
The Real Bottleneck
I've spent two decades building data systems. The one thing that never changes: someone always has to read the failure log, decide what broke, and pick the next repair.
You can have the best LLM in the world. But if your pipeline drops rows, mislabels currencies, or silently converts dates, nobody trusts the output. The bottleneck isn't the model. It's the human sitting between the failure and the fix.
Poor data quality costs organizations up to $5 million on average, and up to $500 million for large-scale projects. One in four organizations feels this hit. The cost isn't the broken data. The cost is the human loop that keeps it from compounding.
Software 3.0 as a Boundary Problem
Software 3.0 is a vague term until you ground it in architecture. Think of it as a cavity wall: two rigid layers of brick with a hollow middle.
The AI lives in that middle gap. It absorbs the vibration and variation of messy data, expanding or contracting to fix discrepancies. The outer bricks stay immovable. They provide the structural integrity that keeps the whole thing standing.
| Era | Primary "Code" | Role of the Human |
|---|---|---|
| Software 1.0 | Explicit Algorithms | Architect & Coder |
| Software 2.0 | Neural Network Weights | Data Curator & Labeler |
| Software 3.0 | Natural Language Prompts | Teacher & Verifier |
The shift isn't about replacing code. It's about shifting the editable surface. Static code becomes programmable operators. Agents find likely repairs in seconds instead of hours. But the contract stays rigid.
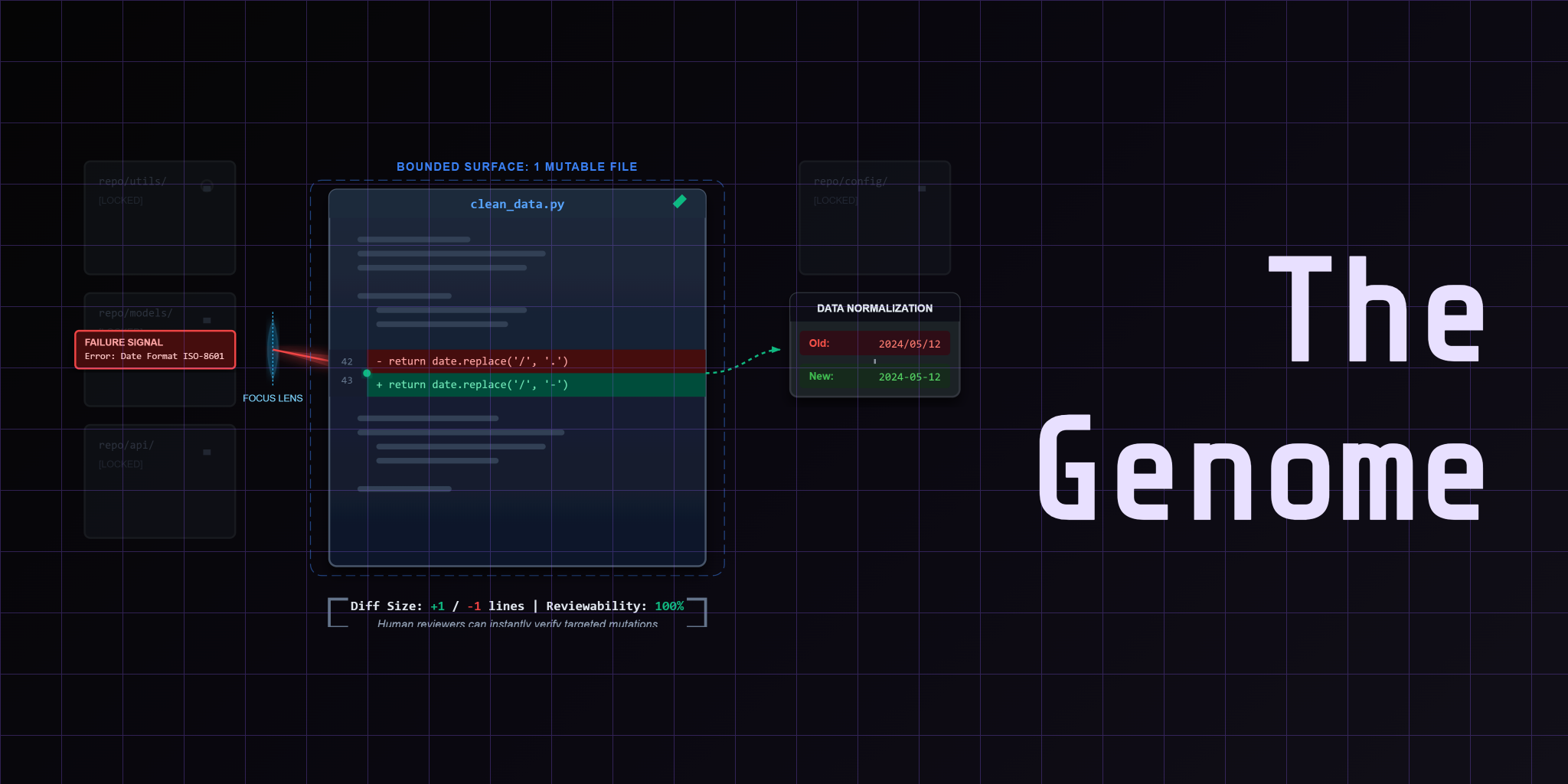
The Bounded Mutation Contract
A self-improving loop only works when the boundary stays narrow. Three rules:
One mutable surface. The loop is allowed to change one file. Not the whole repo. One file keeps diffs reviewable, rollbacks clean, and blame traceable.
One fixed judge. A deterministic referee grades every mutation. Binary pass or fail at the row level. The judge never changes. The data might get harder, but the grading rubric stays fixed.
One visible artifact trail. Every mutation decision logs evidence. Score deltas, genome diffs, token traces. If you can't inspect why a mutation survived or was reverted, you don't have a loop. You have a coin flip.
The contract in practice looks like this:
Four steps. No magic. Read the failure, propose the mutation, run the judge, commit or revert.
Where AutoGen Actually Belongs
Here's the mistake most teams make: they put the agent inside the judge.
The moment the AI grades its own work, the loop becomes untrustworthy. AutoGen belongs at the orchestration seam, not inside the correctness boundary. The framework coordinates repair attempts and candidate generation. Deterministic code decides whether the mutation survives.
The split matters because it keeps the loop inspectable. You can blame a specific mutation. You can roll back cleanly. You can measure whether the loop is actually improving over time.
The CleanLoop Example
The CleanLoop project makes this contract visible through a runnable surface. Five messy finance CSVs feed into a pipeline. The pipeline has two paths:
Deterministic first. Rules handle what they can. Format normalization, type coercion, known edge cases. These rows go straight to the master output.
Mutation second. The unresolved failures — the rows that broke the deterministic path — fall through to the mutation playbook. The LLM proposes a fix. The judge grades it. The loop remembers what worked.
The shipped sample contains 87 input rows across five files. Thirty rows succeed deterministically. Forty-eight succeed through the mutation playbook. Nine stay unresolved. That 99% recovery rate isn't a toy example. It's from a real production system.
The Dashboard Makes It Visible
You can't trust a loop you can't inspect. The Streamlit dashboard turns loop evidence into operator-facing metrics:
- Score deltas per round — was the loop improving or regressing?
- Mutable genome diff — what exactly changed in the code?
- Row-level decisions — which rows succeeded deterministically, which went through mutation, which stayed unresolved?
The dashboard also shows proposal events. When the loop picked up a failure, did it revert? Did it generate a candidate? How did the LLM respond to the context?
That visibility is the difference between a system that learns and one that hallucinates.
Why Lesson 01 Starts Here
Most courses jump straight into code mutation. This one starts with framing.
A self-improving loop only makes sense when you can name the mutable surface, the fixed judge, and the artifact trail before the first mutation runs. Lesson 01 proves that boundary-first design is visible in the project itself.
The README becomes the first navigation surface. The status command shows you what the system sees. The verify gate proves the environment is healthy. Then you run one bounded loop and inspect the evidence.
The Integration Paradox
There's a gap between stochastic AI outputs and deterministic system requirements. Financial pipelines need fixed boundaries. Backend systems need auditability. The AI is inherently probabilistic.
The bounded mutation contract closes that gap. The AI proposes changes within a narrow surface. The deterministic judge enforces the rules. The artifact trail makes every decision reviewable.
That's the posture for the rest of the course. Rules first. Bounded mutation second. Safety always.
Related Reading
- Next: Lesson 02: The Genome — Why the mutation surface must stay narrow to keep diffs reviewable and rollbacks clean.
- Project anchor: CleanLoop Example — See the runnable repo surface that turns the bounded mutation contract into an inspectable workflow.
Next Steps
This article covers the framing behind Lesson 01 of the Self-Evolving Data Engineer course. The full lesson includes a video walkthrough, a live demo of the CleanLoop repo, and a dashboard inspection of the mutation evidence.
Watch Lesson 01: Stop Fixing Pipelines: Build a Self-Evolving AI Data Engineer
Next in series: Lesson 02 locks the exact genome boundary. The course escalates from boundary → genome → orchestration → observability → pressure → search → safety.
The full course and example code are open source on GitHub.
This article is part of the Self-Evolving Data Engineer series. The loop only works when the boundary stays narrow and the enforcement stays fixed.