
A self-improving pipeline doesn't start with an LLM. It starts with a file.
One file. One function. One surface the loop is allowed to mutate. The rest of the system stays fixed. The judge doesn't change. The contract doesn't shift. The only thing that moves is the genome.
Prerequisites
- Read Lesson 01: The Mutation Engine — covers the bounded mutation contract and boundary-first design
- Familiarity with data pipelines and ETL concepts
- Basic understanding of LLMs and agent frameworks
- Python experience (the examples use
autogen-agentchat,pandas, andstreamlit)
The Mutation Surface
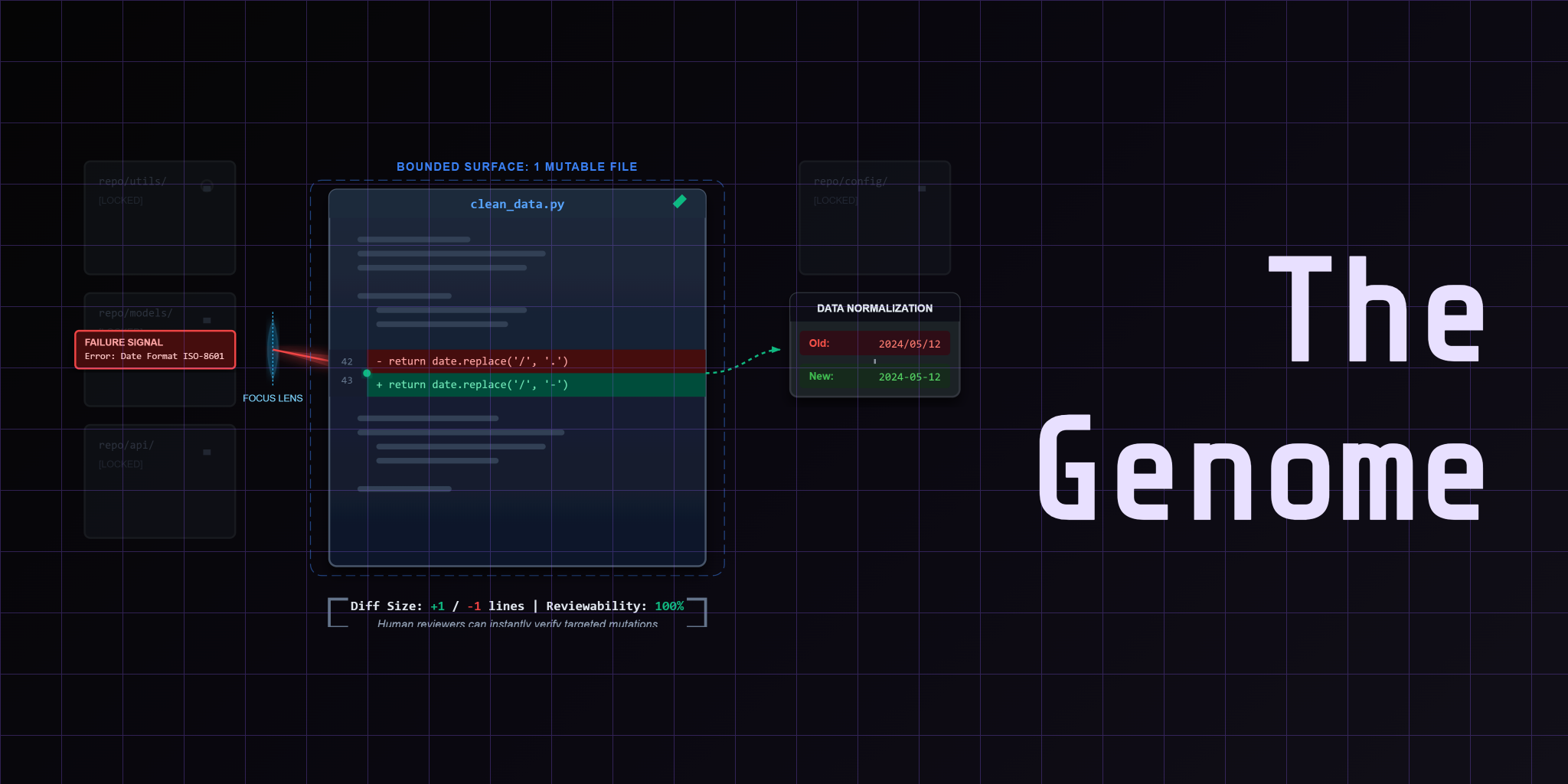
The CleanLoop pipeline has one mutable file. Not the whole repo. One file keeps diffs reviewable, rollbacks clean, and blame traceable.
That file is clean_data.py. It wraps the runtime and delegates to the mutation playbook:
Two lines. That's the genome. The loop proposes changes to this surface. The judge grades the result. If the score improves, the mutation survives. If it doesn't, the loop reverts.
Why One File Matters
When you allow the loop to mutate the whole codebase, you lose auditability. You can't blame a specific change. You can't roll back cleanly. You can't measure whether the loop is actually improving.
The one-file constraint forces discipline. The genome becomes a diff. The diff becomes a log. The log becomes evidence.
| Constraint | Purpose |
|---|---|
| One mutable surface | Keeps diffs reviewable |
| One fixed judge | Enforces binary pass/fail |
| One artifact trail | Makes mutations inspectable |
As covered in Lesson 01, the bounded mutation contract is the foundation. The genome is the surface that contract operates on.
The Runtime Split
The genome doesn't contain business logic. It delegates to the runtime. The runtime splits rows into two paths: deterministic first, mutation second.
The deterministic path handles known edge cases. Format normalization, type coercion, currency parsing. These rows succeed without the LLM.
The mutation playbook handles the rest. The LLM proposes a fix. The judge grades it. The loop remembers what worked.
The Starter Genome
Not every loop starts from scratch. The starter genome is a deterministic-only baseline. Same shape as the mutable genome, but it calls a different runtime path.
The starter genome lets you reset the loop. If the mutation drifts too far, or if you want to compare deterministic vs. stochastic recovery, you can fall back to the baseline.
The Mutation Playbook
The runtime doesn't call the LLM directly. It routes through the mutation playbook. The playbook normalizes tokens, resolves rules, and builds the candidate row.
The playbook keeps the LLM out of the runtime path. The runtime routes. The playbook resolves. The LLM proposes. The judge grades.
Why the Judge Stays Fixed
The moment the judge changes, the loop becomes untrustworthy. You can't measure improvement if the grading rubric shifts. You can't blame a mutation if the judge learns to pass everything.
The fixed judge enforces binary assertions — row count and column drift checks. No fuzzy scoring. No partial credit. The judge says pass or fail. The loop uses the delta to decide whether to commit or revert.
The Orchestration Seam
AutoGen sits at the orchestration seam, not inside the judge. The framework coordinates repair attempts and candidate generation. Deterministic code decides whether the mutation survives.
The split keeps the loop inspectable. You can blame a specific mutation. You can roll back cleanly. You can measure whether the loop is actually improving over time.
The Evidence Trail
You can't trust a loop you can't inspect. The artifact trail logs every mutation decision:
- Score deltas per round — was the loop improving or regressing?
- Genome diffs — what exactly changed in
clean_data.py? - Row-level decisions — which rows succeeded deterministically, which went through mutation, which stayed unresolved?
The Streamlit dashboard turns this evidence into operator-facing metrics. That's the difference between a system that learns and one that hallucinates.
Why Lesson 02 Locks the Genome
Lesson 01 proves the boundary. Lesson 02 locks the genome. You can't build a self-improving loop if you don't know what's allowed to change.
The genome becomes the first concrete artifact. From here, the course escalates to orchestration, observability, pressure testing, and safety.
Related Reading
- Previous: Lesson 01: The Mutation Engine — Why the loop needs a bounded contract before the first mutation runs.
- Next: Lesson 03: The Orchestrator — Why the loop needs a control shell around the LLM to coordinate repair attempts.
- Project anchor: CleanLoop Example — Trace the bounded genome, fixed referee, and starter baseline in the runnable example.
Next Steps
This article covers the genome constraint behind Lesson 02 of the Self-Evolving Data Engineer course. The full lesson includes a live demo of the genome diff, a walkthrough of the mutation playbook, and a dashboard inspection of recovery rates.
Watch Lesson 02: [Link coming soon]
Previous in series: Lesson 01: The Mutation Engine
Next in series: Lesson 03: The Orchestrator moves to orchestration. The loop learns to coordinate repair attempts across multiple failure modes.
The full course and example code are open source on GitHub.
This article is part of the Self-Evolving Data Engineer series. The loop only works when the boundary stays narrow and the enforcement stays fixed.