
You can give an LLM every failure log in the world. But without a control shell that reads the evidence, proposes a fix, verifies the result, and decides survival, you don't have a loop. You have a suggestion engine with no selection rule.
That is the gap between a system that learns and one that guesses.
Prerequisites
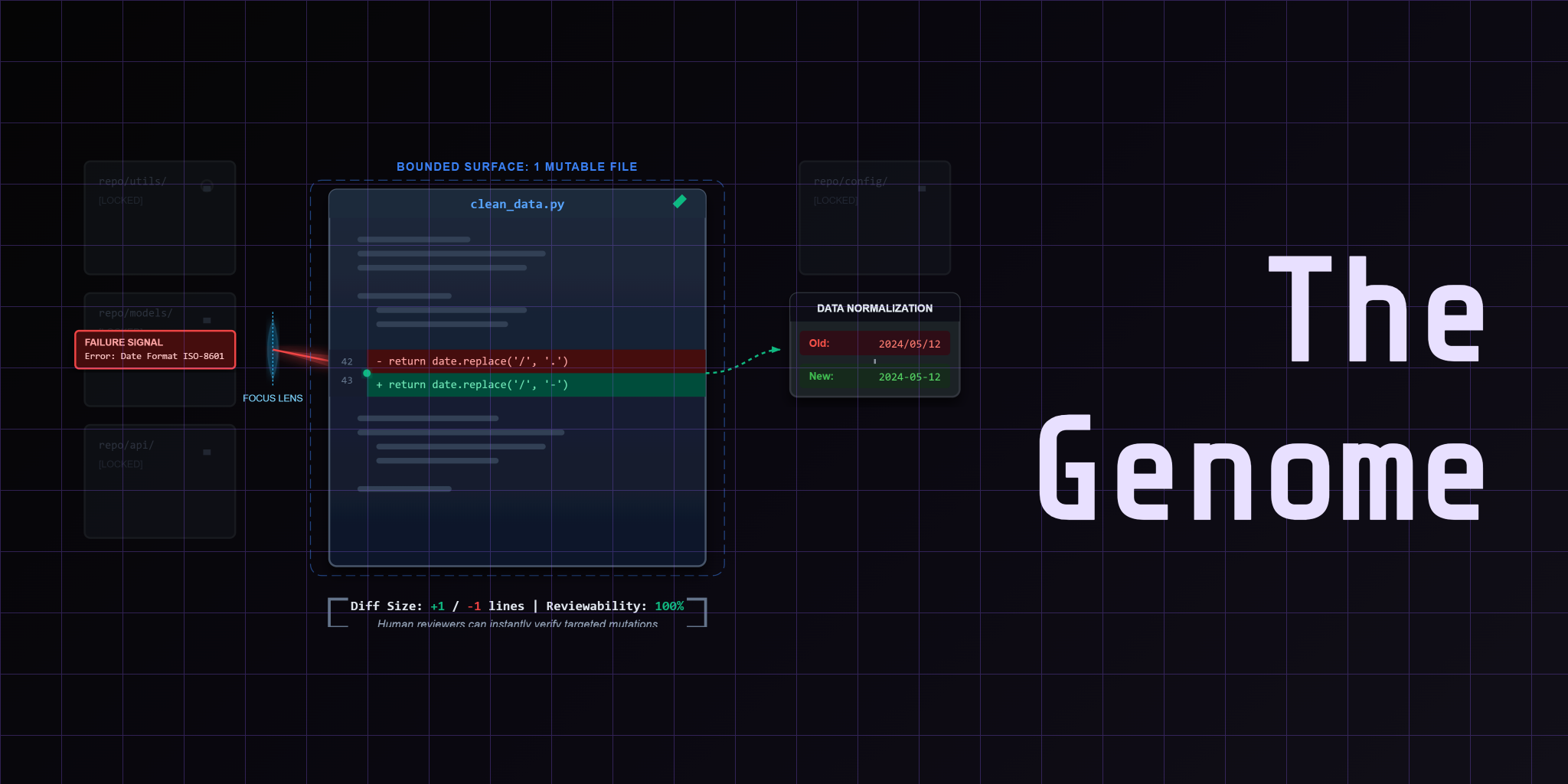
- Lessons 01 and 02 of this course (mutation engine framing and genome boundary)
- Familiarity with the bounded mutation contract: one mutable file, one fixed judge, one artifact trail
- Basic understanding of what an AI agent framework can do (AutoGen is used in the examples, but the pattern applies broadly)
The Problem After the Genome
Lessons 01 and 02 set the boundary. You have one mutable genome file. You have a fixed referee that grades mutations. You know the contract.
But then the question becomes: who reads the failure, asks for the next mutation, and decides whether the candidate survives?
If the answer is "the LLM decides," the loop becomes untrustworthy. The model grades its own work. No blame trace. No clean rollback. No audit trail.
If the answer is "a human reads the log and manually patches the genome," the loop doesn't scale. You're back to the original bottleneck.
The orchestrator is the answer. A deterministic control shell around one bounded LLM call.
Reader, Repair Forge, Crucible
The orchestrator splits into three stations. Each one has a job. Each one stays explicit.
The reader grounds the next move in failure evidence. It does not solve the task. It compresses repeated failures into one focus area and one coaching hint. If four rows keep failing currency normalization, the focus is currency normalization. Not the whole dataset.
This compression is metacognition. Not magic. Evidence-driven narrowing.
The repair forge takes that focus area and asks the LLM for a bounded mutation. One file change. One hypothesis. The model can suggest. It does not get to declare success.
The crucible re-runs the candidate against the fixed judge. Binary pass or fail at the row level. If the score improves, the mutation commits. If it doesn't, the loop reverts to the previous genome.
That three-station split keeps the loop deterministic around the agentic seam. The LLM is one station. The judge, the reset, and the commit decision stay explicit.
| Station | Role | Who Runs It |
|---|---|---|
| Reader | Compresses failures into focus | Deterministic code |
| Repair Forge | Proposes mutation | LLM (bounded) |
| Crucible | Grades candidate, decides survival | Fixed referee |
One Round Is One Controlled Experiment
The most important thing about the orchestrator is not that it keeps trying. It's that one round is an atomic experiment.
Run the current genome. Judge the output. Compress failures. Propose one mutation. Re-evaluate the candidate. Commit or revert.
That order matters. You cannot skip steps. If you propose before you judge, you have no evidence to ground the mutation. If you commit before you re-evaluate, you have no selection rule.
When a candidate gets rejected, that is still progress. The judge proved the change wasn't good enough. The revert path proved the loop stays bounded after a bad idea. The history record preserves why the loop focused where it did.
Here is what one bounded round looks like in the terminal:
The model proposed a fix. The judge rejected it. The loop reverted. No damage. No drift. The baseline stays clean for the next round.
Why Revert Matters More Than Commit
Most teams celebrate when the loop finds a working mutation. They should celebrate when the loop reverts a bad one.
A revert proves three things:
- The judge works. The referee caught a mutation that didn't improve the score. If the judge always passed, you'd have no selection rule.
- The boundary holds. The loop restored the previous genome. No partial state. No half-applied changes that corrupt the baseline.
- The trail is preserved. The history record saves why the mutation was rejected. Future rounds can learn from that failure.
A loop that only commits is not a loop. It's a one-way mutation generator. The ability to roll back is what makes the system self-improving instead of self-degrading.
The Artifact Trail
You cannot trust a loop you cannot inspect. The orchestrator saves structured artifacts after every round:
finance_eval_history.json— score deltas across rounds, showing improvement or regressionfinance_strategy.json— the metacognition snapshot, what the loop focused on and whyfinance_round_logs.jsonl— per-round structured logs with failures, actions, and strategy shiftsproposal-events.jsonl— which LLM attempt was selected and what it cost
That trail turns iteration into learning. Without it, each round is a transient event. With it, you can chart score movement, trace why the loop shifted focus, and prove the system is actually improving.
Where AutoGen Fits
AutoGen (or any agent framework) sits inside the repair forge. It generates the mutation proposal. That's it.
The mistake teams make is putting the agent inside the judge. The moment the AI grades its own work, the loop becomes untrustworthy. The framework coordinates repair attempts. Deterministic code decides whether the mutation survives.
The split matters because it keeps the loop auditable. You can blame a specific mutation. You can roll back cleanly. You can measure whether the loop is improving over time.
The Integration Gap
There is a gap between stochastic AI outputs and deterministic system requirements. Data pipelines need fixed boundaries. Financial systems need auditability. The AI is inherently probabilistic.
The orchestrator closes that gap. The AI proposes within a narrow surface. The deterministic judge enforces the rules. The artifact trail makes every decision reviewable.
But the orchestrator alone is not enough. You need to see the evidence. You need dashboards that show score movement, row-level decisions, and proposal traces. That is why the next lesson in the course is observability.
Orchestration without observability does not scale. If you cannot inspect the evidence trail, you cannot safely widen the search space or trust the next stage of autonomy.
Trade-offs
The orchestrator is not free. It introduces latency. Each round requires a full re-evaluation. That means the loop is slower than a raw LLM call.
The trade-off is intentional. Speed without verification is not improvement. It's just faster guessing. The control shell ensures that every mutation is graded before it persists.
If you need faster iteration, you can parallelize proposals (best-of-N search). But the commit decision stays sequential. One candidate, one judge, one clear pass or fail.
Related Reading
- Previous: Lesson 02: The Genome — Why the mutation surface must stay narrow to keep diffs reviewable and rollbacks clean.
- Next: Lesson 04: Observability & The Feedback Signal — Why the loop needs external memory to make every round reviewable.
- Project anchor: CleanLoop Example — Follow the repo surface that turns reset, proposal, verification, and revert into one bounded round.
Next Steps
This article covers the orchestrator — the control shell that turns failure into the next verified attempt. The full lesson includes a video walkthrough, a live demo of one bounded loop run, and a dashboard inspection of the mutation evidence.
Watch Lesson 03: Stop Fixing Data Pipelines: Build an AI Orchestrator with AutoGen
Next in series: Lesson 04 makes the loop observable. You need dashboards, traces, and row-level evidence before the system gets more autonomous.
The full course and example code are open source on GitHub.
This article is part of the Self-Evolving Data Engineer series. The loop only works when the control shell stays explicit and the LLM stays bounded.